
Изначально у меня данные собирались через Google формы и вся информация уходила с Google таблиц в Data lens, но в современных реалиях, что гугл не прикроет или гугл не прикроют, нужно приспосабливаться, Яндекс работает не много по другому, можно выводить данные с яндекс форм в data lens и есть инструкция, но нужно бесплатно с теми ресурсами которые есть.
Реализовать получилось следующим образом. В яндекс формах есть пункт Интеграция. Там создаем отправку на почту и дальше как на скрине ниже. Адрес свой, тема и текст подбираете на свой вкус нажав на плюсик. Теперь Вам на почту будет прилетать письмо в HTML от туда мы и будем забирать наши данные.
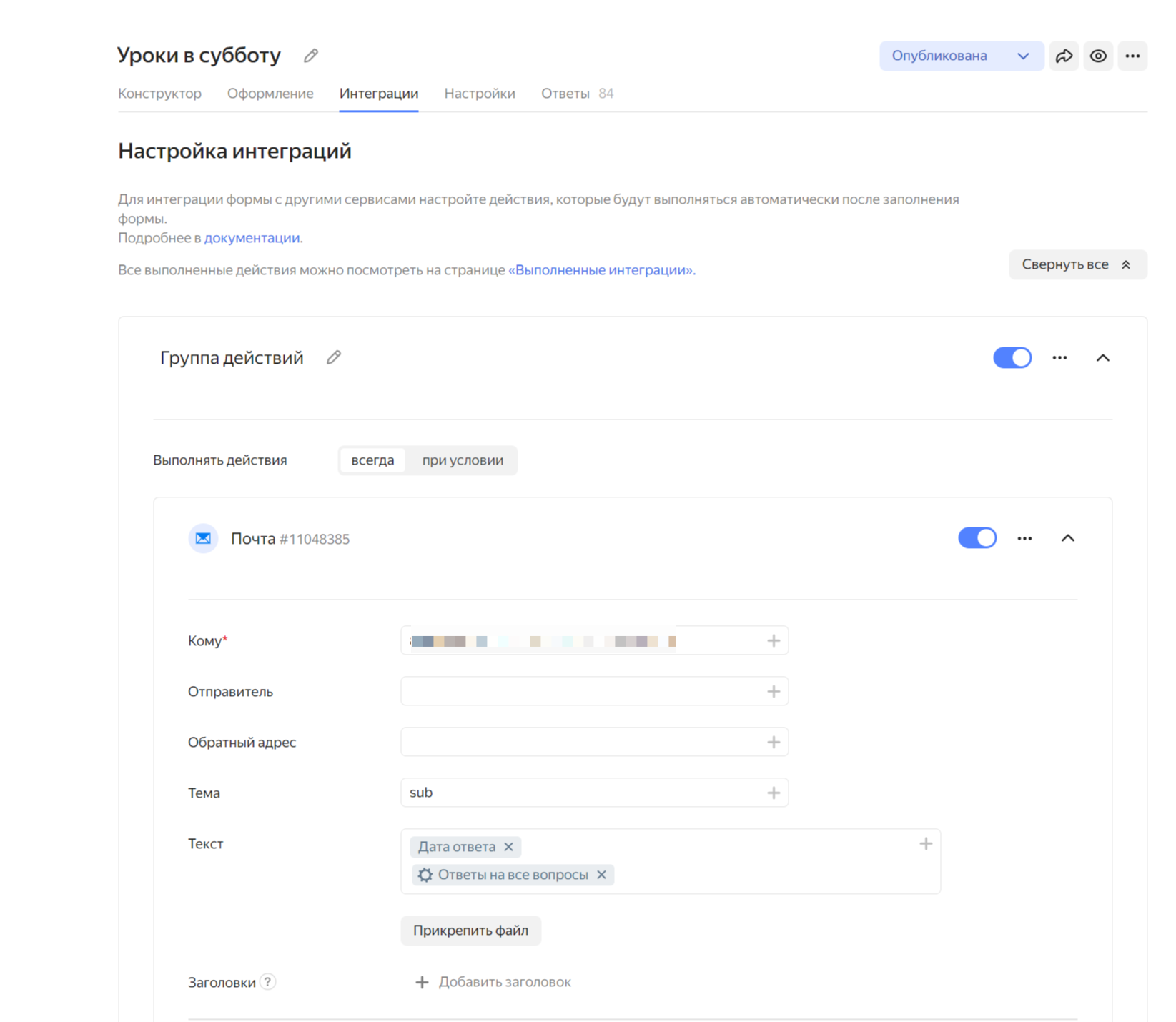
Поверьте я совсем не имею никакого отношения к IT по этому дальше совсем дичь с костылями. Но ладно.
У меня есть сервер где крутится сайт, поэтому я и запихнул скрипт на него, но Вы можете использовать его и на своем компьютере. Кратко, что он делает.
Вам нужно создать таблицу на яндекс диске, создать токен (вот ссылка на статью как это правильно сделать), почту у меня прилетала на Mail.ru по этому для скрипта нужен еще специальный отдельный пароль, вот инструкция, остальные параметры оставлю в скрипте. Если у Вас другой ящик, значит и данные свои подставите. Все остальные пояснения постараюсь оставить в коде. Ну а в Data lens просто данные берете из файла который обновляется скриптом.
P.S. Самое сложное (опять костыль) — это извлечение данных из письма. Для этого в консоль выводится информация о том, как выглядит письмо, с помощью которой мы и соотносим строку с колонкой таблицы, в которую нужно внести данные.
# Обработка данных
new_row = {
‘Отметка времени’: lines[1], #Название столбца: строка в письме
‘класс’: lines[5], #Название столбца: строка в письме
‘предмет’: lines[7], #Название столбца: строка в письме
‘ссылка на урок (Только ссылка)’: lines[9], #Название столбца: строка в письме
‘Дата урока’: lines[3], #Название столбца: строка в письме
}
import pandas as pd
import imaplib
import email
from email.header import decode_header
from datetime import datetime
from bs4 import BeautifulSoup
import requests
from io import BytesIO
# Ссылка на файл на Яндекс Диске
public_file_url = 'Ссылка на Вашу таблицу'
ya_disk_token = 'Ваш токен для Яндекса'
# Функция для получения настоящей ссылки скачивания Яндекс Диск
def get_yandex_disk_download_url(public_url):
base_url = 'https://cloud-api.yandex.net/v1/disk/public/resources/download?public_key='
response = requests.get(base_url + public_url)
response.raise_for_status()
download_url = response.json().get('href')
return download_url
# Получение файла
download_url = get_yandex_disk_download_url(public_file_url)
file_content = requests.get(download_url).content
xls = pd.ExcelFile(BytesIO(file_content))
# Листы в Excel файле ( Тут названия моих листов)
sheet_name_responses = 'Ответы на форму (1)_conflict142'
sheet_name_target = 'Лист3'
# Чтение данных из Excel
responses_df = pd.read_excel(xls, sheet_name=sheet_name_responses)
target_df = pd.read_excel(xls, sheet_name=sheet_name_target)
# Подключение к почтовому ящику
username = 'Ваш_адрес@mail.ru' # Ваш email
password = 'Ваш пароль' # Ваш пароль
mail = imaplib.IMAP4_SSL('imap.mail.ru', 993)
mail.login(username, password)
mail.select('inbox') # Название папки с письмами
# Поиск непрочитанных писем с темой Которую Вы выбрали при отправке из Яндекс форм
status, messages = mail.search(None, '(UNSEEN SUBJECT "Ваша Тема")')
messages = messages[0].split()
new_data_added = False
if not messages:
print('Непрочитанных писем с темой "Ваша Тема" не найдено.')
else:
for msg_num in messages:
res, msg = mail.fetch(msg_num, '(RFC822)')
msg = email.message_from_bytes(msg[0][1])
# Декодирование заголовка
subject, encoding = decode_header(msg['Subject'])[0]
if isinstance(subject, bytes):
subject = subject.decode(encoding) if encoding else subject.decode()
# Получение тела письма
body = ''
if msg.is_multipart():
for part in msg.walk():
content_type = part.get_content_type()
content_disposition = str(part.get("Content-Disposition"))
if "attachment" not in content_disposition and "inline" not in content_disposition:
try:
part_payload = part.get_payload(decode=True)
if part_payload: # Проверка на None
charset = part.get_content_charset()
if charset:
part_payload = part_payload.decode(charset, errors='replace')
else:
part_payload = part_payload.decode(errors='replace')
if content_type == "text/plain":
body += part_payload
elif content_type == "text/html" and not body.strip():
body = part_payload # Попробуем HTML, если нет текста
except Exception as e:
print(f"Ошибка декодирования части письма: {e}")
else:
try:
body = msg.get_payload(decode=True).decode(errors='replace')
except Exception as e:
print(f"Ошибка декодирования тела письма: {e}")
if not body.strip(): # Если тело письма пустое после всех попыток
print("Тело письма пустое, пропускаем.")
continue
# Если тело письма в HTML, преобразуем его в текст
if "<html" in body:
soup = BeautifulSoup(body, 'html.parser')
body = soup.get_text()
print("Тело письма:\n" + body)
lines = body.split('\n')
lines = [line for line in lines if line.strip()]
if len(lines) < 8:
print('Письмо не содержит достаточно строк для обработки.')
continue
# Обработка данных
new_row = {
'Отметка времени': lines[1], #Название столбца: строка в письме
'класс': lines[5], #Название столбца: строка в письме
'предмет': lines[7], #Название столбца: строка в письме
'ссылка на урок (Только ссылка)': lines[9], #Название столбца: строка в письме
'Дата урока': lines[3], #Название столбца: строка в письме
}
responses_df = pd.concat([responses_df, pd.DataFrame([new_row])], ignore_index=True)
new_data_added = True
print('Данные успешно добавлены в таблицу.')
# Отмечаем письмо как прочитанное
mail.store(msg_num, '+FLAGS', '\\Seen')
# Проверка столбцов в DataFrame
print("Имена столбцов в responses_df:", responses_df.columns)
# Проверка были ли новые данные для занесения в таблицу
if new_data_added:
# Здесь идет проверка по дате, так как мне необходимо было убирать данные которые старше текущей даты
# Перенос строк с датами меньше текущей даты из responses_df в target_df
today = pd.Timestamp(datetime.today())
dates = pd.to_datetime(responses_df['Дата урока'], errors='coerce')
rows_to_move = responses_df[dates < today]
target_df = pd.concat([target_df, rows_to_move], ignore_index=True)
responses_df = responses_df.drop(rows_to_move.index)
# Сохранение обновленных данных в память
output = BytesIO()
with pd.ExcelWriter(output, engine='openpyxl') as writer:
responses_df.to_excel(writer, sheet_name=sheet_name_responses, index=False)
target_df.to_excel(writer, sheet_name=sheet_name_target, index=False)
output.seek(0)
# Получение ссылки для загрузки на Яндекс Диск
upload_link_response = requests.get(
"https://cloud-api.yandex.net/v1/disk/resources/upload",
headers={"Authorization": f"OAuth {ya_disk_token}"},
params={"path": "app:/Дистант.xlsx", "overwrite": "true"}
)
upload_link_data = upload_link_response.json()
print("API Ответ на запрос ссылки загрузки:", upload_link_data)
upload_url = upload_link_data.get("href")
if upload_url:
# Загрузка файла на Яндекс Диск
response = requests.put(upload_url, files={"file": output})
if response.status_code == 201:
print('Загрузка обновленного файла завершена успешно.')
else:
print(f'Ошибка загрузки: {response.status_code}')
else:
print("Ошибка получения ссылки на загрузку")
else:
print('Новых данных для добавления в таблицу нет.')
print('Перенос завершен. Данные успешно обновлены, если были новые письма.')
mail.logout()